文章目录
- 前言
- 幂等生产者
- 幂等生产者的工作原理
- 幂等生产者的局限性
- 如何使用幂等生产者
- 事务
- 事务的应用场景
- 事务可以解决哪些问题
- 事务是如何保证精确一次性的
- 使用事物 API
- 事物的工作原理
- 事务的性能
前言
Kafka的精确一次性语义与国际象棋正好相反:要理解它不容易,但用起来很简单。
本文将介绍 Kafka 实现精确一次性语义的两个关键机制:幂等生产者(避免由重试机制导致的重复处理)和事务(Streams精确一次性语义的基础)。
通过一个配置就可以启用它们,这样就可以很方便地在要求更少重复和更高正确性的应用程序中使用Kafka了。
幂等生产者
Kafka的幂等生产者可以自动检测并解决消息重复问题。
幂等生产者的工作原理
唯一标识
- 如果启用了幂等生产者,那么每条消息都将包含生产者ID(PID)和序列号。我们将它们与目标主题和分区组合在一起,用于唯一标识一条消息。
- broker会用这些唯一标识符跟踪写入每个分区的最后5条消息。为了减少每个分区需要跟踪的序列号数量,生产者需要将
max.inflight.requests设置成5或更小的值(默认值是5)。
错误指标记录
- 如果broker收到之前已经收到过的消息,那么它将拒绝这条消息,并返回错误。
- 生产者会记录这个错误,并反映在指标当中,但不抛出异常,也不触发告警。在生产者客户端,错误将被添加到
record-error-rate指标当中。在broker端,错误是ErrorsPerSec指标的一部分(RequestMetrics类型)。
乱序错误
- 如果 broker 收到一个非常大的序列号该怎么办?如果broker期望消息2后面跟着消息3,但收到了消息27,那么这个时候该怎么办?在这种情况下,broker将返回“乱序”错误。如果使用了不带事务的幂等生产者,则这个错误可能会被忽略。
虽然生产者在遇到“乱序”异常后将继续正常运行,但这个错误通常说明生产者和broker之间出现了消息丢失——如果broker在收到消息2之后直接收到消息27,那么说明从消息3到消息26一定发生了什么。如果在日志中看到这样的错误,那么最好重新检查一下生产者和主题的配置,确保为生产者配置了高可靠性参数,并检查是否发生了不彻底的首领选举。
一般发生下边两种情况会导致幂等性被破坏:生产者重启和broker故障。
生产者重启
- 当一个生产者发生故障时,我们通常会创建新生产者来代替它——可能是手动重启机器或使用像Kubernetes这样提供了自动故障恢复功能的复杂框架。关键的问题在于,如果启用了幂等生产者,那么生产者在重启时就会连接broker并生成生产者ID。
- 生产者在每次初始化时都会产生一个新ID(假设没有启用事务)。这意味着如果一个生产者发生故障,取代它的生产者发送了一条旧生产者已经发送过的消息,那么broker将无法检测到重复,因为这两条消息有不同的生产者ID和序列号,将被视为两条不同的消息。需要注意的是,如果一个旧生产者被挂起,但在替代它的新生产者启动之后又“活”过来了,那么情况也一样——旧生产者不会被认为是“僵尸”,它们是两个拥有不同ID的生产者。
broker故障
- 新首领选举:当一个broker发生故障时,控制器将为首领副本位于这个broker上的分区选举新首领。假设我们有一个生产者,它向主题A的分区0生成消息,分区0的首领副本在broker 5上,跟随者副本在broker 3上。如果broker 5发生故障,那么broker 3就会成为新首领。生产者通过元数据协议发现broker 3是新首领,并开始向它生成消息。
- 新首领保证不重复发送消息: 每次生成新消息时,首领都会用最后5个序列号更新内存中的生产者状态。每次从首领复制新消息时,跟随者副本都会更新自己的内存。当跟随者成为新首领时,它的内存中已经有了最新的序列号,并且可以继续验证新生成的消息,不会有任何问题或延迟。
- 旧首领重启:但是,如果旧首领又“活”过来了,会发生什么呢?在重启之后,内存中没有旧首领的生产者状态。为了能够恢复状态,每次在关闭或创建日志片段时broker都会将生产者状态快照保存到文件中。broker在启动时会从快照文件中读取最新状态,然后通过复制当前首领来更新生产者状态。当它准备好再次成为首领时,内存中已经有了最新的序列号。
- 新快照生成:如果broker发生崩溃,但没有更新最后一个快照,会发生什么呢?生产者ID和序列号也是Kafka消息格式的一部分。在进行故障恢复时,我们将通过读取旧快照和分区最新日志片段里的消息来恢复生产者状态。等故障恢复完成,一个新的快照就保存好了。
- 故障期间没有消息发送: 如果分区里没有消息,会发生什么呢?假设某个主题的数据保留时间是两小时,但在过去的两小时内没有新消息到达——如果broker发生崩溃,则没有消息可以用来恢复状态。幸运的是,没有消息也就意味着没有重复消息。我们可以立即开始接收新消息(同时将状态缺失的警告信息记录下来),并创建生产者状态。
幂等生产者的局限性
幂等生产者只能防止由生产者内部重试逻辑引起的消息重复。对于使用同一条消息调用两次producer.send()就会导致消息重复的情况,即使使用幂等生产者也无法避免。
这是因为生产者无法知道这两条消息实际上是一样的。通常建议使用生产者内置的重试机制,而不是在应用程序中捕获异常并自行进行重试。使用幂等生产者是在进行重试时避免消息重复的最简单的方法。
幂等生产者只能防止因生产者自身的重试机制而导致的消息重复,不管这种重试是由生产者、网络还是broker错误所导致。
如何使用幂等生产者
幂等生产者使用起来非常简单,只需在生产者配置中加入enable.idempotence=true。如果生产者已经配置了acks=all,那么在性能上就不会有任何差异。在启用了幂等生产者之后,会发生下面这些变化:
- 为了获取生产者ID,生产者在启动时会调用一个额外的API。
- 每个消息批次里的第一条消息都将包含生产者ID和序列号(批次里其他消息的序列号基于第一条消息的序列号递增)。这些新字段给每个消息批次增加了96位(生产者ID是长整型,序列号是整型),这对大多数工作负载来说几乎算不上是额外的开销。
- broker将会验证来自每一个生产者实例的序列号,并保证没有重复消息。
- 每个分区的消息顺序都将得到保证,即使
max.in.flight.requests.per.connection被设置为大于1的值(5是默认值,这也是幂等生产者可以支持的最大值)。
事务
Kafka的事务机制是专门为流式处理应用程序而添加的。因此,它非常适用于流式处理应用程序的基础模式,即“消费–处理–生产”。事务可以保证流式处理的精确一次性语义——在更新完应用程序内部状态并将结果成功写入输出主题之后,对每个输入消息的处理就算完成了。
事务的应用场景
一些流式处理应用程序对准确性要求较高,特别是如果处理过程包含了聚合或连接操作,那么事务对它们来说就会非常有用。
如果流式处理应用程序只进行简单的转换和过滤,那么就不需要更新内部状态,即使出现了重复消息,也可以很容易地将它们过滤掉。
但是,如果流式处理应用程序对几条消息进行了聚合,一些输入消息被统计了不止一次,那么就很难知道结果是不是错误的。如果不重新处理输入消息,则不可能修正结果。
金融行业的应用程序就是典型的复杂流式处理的例子,在这些应用程序中,精确一次性被用于保证精确的聚合结果。不过,因为可以非常容易地在Streams应用程序中启用精确一次性保证,所以已经有非常多的应用场景(如聊天机器人)启用了这个特性。
事务可以解决哪些问题
应用程序崩溃导致的重复处理
-
消费者处理消息有两个必须的步骤:
一:处理消费的消息,并且将消息写入目标主题。
二:提交消费消息偏移量 -
假设在消费处理完消息后,提交偏移量前,消费者应用程序奔溃,将会导致重复消费的问题。
“僵尸”应用程序导致的重复处理
- 消费者在处理消息之前就已经挂掉了,然后会有新的消费者接收该分区,消费处理已挂掉消费者需要处理的消息,这个时候还没有问题。
- 但是,此时之前挂掉的消费者又恢复了,然后开始继续处理之前的分区的数据发送到目标主题,这个时候就会出现消息重复的问题。
- 一个“死亡”但不知道自己已经“死亡”的消费者被称为“僵尸”。在这个场景中,如果没有额外的保证,则“僵尸”消费者可以向输出主题生成结果,进而导致重复。
事务是如何保证精确一次性的
继续以流式处理应用程序为例。它会从一个主题读取数据,对数据进行处理,再将结果写入另一个主题。精确一次处理意味着消费、处理和生产都是原子操作,要么提交偏移量和生成结果这两个操作都成功,要么都不成功。我们要确保不会出现只有部分操作执行成功的情况(提交了偏移量但没有生成结果,反之亦然)。
为了支持这种行为,Kafka事务引入了原子多分区写入的概念。我们知道,提交偏移量和生成结果都涉及向分区写入数据,结果会被写入输出主题,偏移量会被写入consumer_offsets主题。如果可以打开一个事务,向这两个主题写入消息,如果两个写入操作都成功就提交事务,如果不成功就中止,并进行重试,那么就会实现我们所追求的精确一次性语义。
开启生产者事物配置参数
下图是一个简单的流式处理应用程序,它会在执行原子多分区写入的同时提交消息偏移量:

- 为了启用事务和执行原子多分区写入,我们使用了事务性生产者。事务性生产者实际上就是一个配置了
transactional.id并用initTransactions()方法初始化的Kafka生产者。 - 与
producer.id(由broker自动生成)不同,transactional.id是一个生产者配置参数,在生产者重启之后仍然存在。 - 实际上,
transactional.id主要用于在重启之后识别同一个生产者。broker维护了transactional.id和producer.id之间的映射关系,如果对一个已有的transactional.id再次调用initTransactions()方法,则生产者将分配到与之前一样的producer.id,而不是一个新的随机数。
隔离僵尸程序
- 防止“僵尸”应用程序实例重复生成结果需要一种“僵尸”隔离机制,或者防止“僵尸”实例将结果写入输出流。通常可以使用epoch来隔离“僵尸”。
- 在调用
initTransaction()方法初始化事务性生产者时,Kafka会增加与transactional.id相关的epoch。带有相同transactional.id但epoch较小的发送请求、提交请求和中止请求将被拒绝,并返回FencedProducer错误。旧生产者将无法写入输出流,并被强制close(),以防止“僵尸”引入重复记录。 - Kafka 2.5及以上版本支持将消费者群组元数据添加到事务元数据中。这些元数据也被用于隔离“僵尸”,在对“僵尸”实例进行隔离的同时允许带有不同事务ID的生产者写入相同的分区。
在很大程度上,事务是一个生产者特性。创建事务性生产者、开始事务、将记录写入多个分区、生成偏移量并提交或中止事务,这些都是由生产者完成的。然而,这些还不够。以事务方式写入的记录,即使是最终被中止的部分,也会像其他记录一样被写入分区。消费者也需要配置正确的隔离级别,否则将无法获得我们想要的精确一次性保证。
消费者开启事物参数配置
- 我们通过设置
isolation.level参数来控制消费者如何读取以事务方式写入的消息。 - 如果设置为
read_committed,那么调用consumer.poll()将返回属于已成功提交的事务或以非事务方式写入的消息,它不会返回属于已中止或执行中的事务的消息。 - 默认的隔离级别是
read_uncommitted,它将返回所有记录,包括属于执行中或已中止的事务的记录。 - 配置成
read_committed并不能保证应用程序可以读取到特定事务的所有消息。也可以只订阅属于某个事务的部分主题,这样就可以只读取部分消息。此外,应用程序无法知道事务何时开始或结束,或者哪些消息是哪个事务的一部分。 - 下图对比了在read_committed隔离级别和默认的read_uncommitted隔离级别下,消费者可以看到哪些记录:
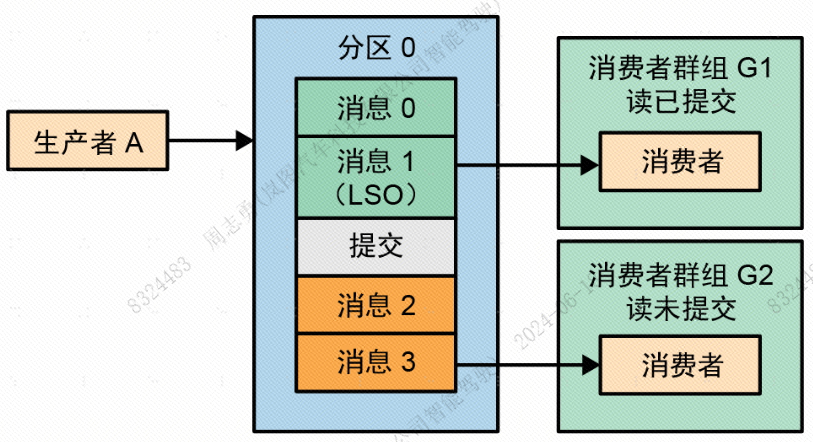
- read_committed隔离级别下的消费者比默认隔离级别下的消费者滞后
- 为了保证按顺序读取消息,read_committed隔离级别将不返回在事务开始之后(这个位置也被叫作最后稳定偏移量,last stable offset,LSO)生成的消息。这些消息将被保留,直到事务被生产者提交或终止,或者事务超时(通过
transaction.timeout.ms参数指定,默认为15分钟)并被broker终止。长时间使事务处于打开状态会导致消费者延迟,从而导致更高的端到端延迟。 - 流式处理应用程序的输出结果具备了精确一次性保证,即使输入消息是以非事务方式写入的。原子多分区写入可以保证在将输出记录提交到输出主题的同时也提交了输入记录的偏移量,所以输入记录不会被重复处理。
使用事物 API
Properties producerProps = new Properties();
producerProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
producerProps.put(ProducerConfig.CLIENT_ID_CONFIG, "DemoProducer");
producerProps.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionalId); ➊
producer = new KafkaProducer<>(producerProps);
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
consumerProps.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); ➋
consumerProps.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed"); ➌
consumer = new KafkaConsumer<>(consumerProps);
producer.initTransactions(); ➍
consumer.subscribe(Collections.singleton(inputTopic)); ➎
while (true) {
try {
ConsumerRecords<Integer, String> records =
consumer.poll(Duration.ofMillis(200));
if (records.count() > 0) {
producer.beginTransaction(); ➏
for (ConsumerRecord<Integer, String> record : records) {
ProducerRecord<Integer, String> customizedRecord = transform(record); ➐
producer.send(customizedRecord);
}
Map<TopicPartition, OffsetAndMetadata> offsets = consumerOffsets();
producer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());➑
producer.commitTransaction(); ➒
}
} catch (ProducerFencedException|InvalidProducerEpochException e) { ➓
throw new KafkaException(String.format(
"The transactional.id %s is used by another process", transactionalId));
} catch (KafkaException e) {
producer.abortTransaction(); ⓫
resetToLastCommittedPositions(consumer);
}}
- ❶ 为生产者配置transactional.id,让它成为一个能够进行原子多分区写入的事务性生产者。事务ID必须是唯一且长期存在的,因为本质上就是用它定义了应用程序的一个实例。
- ❷ 消费者不提交自己的偏移量——生产者会将偏移量提交作为事务的一部分,所以需要禁用自动提交。
- ❸ 在这个例子中,消费者会从输入主题读取数据。假设输入主题中的消息是由事务性生产者写入的(只是为了好玩儿,实际上我们对输入没有硬性要求)。为了干净地读取事务(忽略执行中和已中止的事务),可以将消费者隔离级别设置为read_committed。需要注意的是,除了读取已提交的事务,消费者也会读取非事务性的写入。
- ❹ 事务性生产者要做的第一件事是初始化,包括注册事务ID和增加epoch的值(确保其他具有相同ID的生产者将被视为“僵尸”,并中止具有相同事务ID的旧事务)。
- ❺ 这里使用了消费者订阅API,分配给应用程序实例的分区可以在触发再均衡时发生变更。
- ❻ 我们读取了记录,现在要处理它们并生成结果。这个方法可以保证从调用它开始,一直到事务被提交或被中止,生成的所有内容都是事务的一部分。
- ❼ 在这里处理消息——所有的业务逻辑都在这里。
- ❽ 之前已经提到过,需要将偏移量提交作为事务的一部分,这样可以保证如果生成结果失败,则未成功处理的消息的偏移量将不会被提交。这个方法会将偏移量提交作为事务的一部分。需要注意的是,不要通过其他方式提交偏移量(禁用偏移量自动提交),也不要调用其他提交偏移量的API。通过其他方式提交偏移量将无法提供事务保证。
- ❾ 我们生成了需要的东西,并将偏移量提交作为事务的一部分,现在可以提交事务了。一旦这个方法成功返回,整个事务就完成了,就可以继续读取和处理下一批消息了。
- ❿ 如果遇到这个异常,则说明应用程序实例变成“僵尸”了。我们的应用程序实例可能由于某种原因被挂起或断开连接,而另一个具有相同事务ID的应用程序实例已经在运行当中。很有可能我们启动的事务已经被中止,其他应用程序正在处理这些记录。这个应用程序实例除了优雅地“死去”,别无他法。
- ⓫ 如果在提交事务时遇到错误,则可以中止事务,重置消费者偏移量位置,并进行重试。
事物的工作原理
Kafka事务的基本算法受到了Chandy-Lamport快照的启发,它会将一种被称为“标记”(marker)的消息发送到通信通道中,并根据标记的到达情况来确定一致性状态。
Kafka事务根据标记消息来判断跨多个分区的事务是否被提交或被中止——当生产者要提交一个事务时,它会发送“提交”消息给事务协调器,事务协调器会将提交标记写入所有涉及这个事务的分区。
如果生产者在向部分分区写入提交消息后发生崩溃,该怎么办?Kafka事务使用两阶段提交和事务日志来解决这个问题。总的来说,这个算法会执行如下步骤:
- 记录正在执行中的事务,包括所涉及的分区
- 记录提交或中止事务的意图——一旦被记录下来,到最后要么被提交,要么被中止。
- 将所有事务标记写入所有分区。
- 记录事务的完成情况。
要实现这个算法,Kafka需要一个事务日志。这里使用了一个叫作 __transaction_state的内部主题。
事务的性能
- 事务给生产者带来了一些额外的开销。事务ID注册在生产者生命周期中只会发生一次。分区事务注册最多会在每个分区加入每个事务时发生一次,然后每个事务会发送一个提交请求,并向每个分区写入一个额外的提交标记。事务初始化和事务提交请求都是同步的,在它们成功、失败或超时之前不会发送其他数据,这进一步增加了开销。
- 需要注意的是,生产者在事务方面的开销与事务包含的消息数量无关。因此,一个事务包含的消息越多,相对开销就越小,同步调用次数也就越少,从而提高了总体吞吐量。
- 在消费者方面,读取提交标记会增加一些开销。事务对消费者的性能影响主要是在read_committed隔离级别下的消费者无法读取未提交事务所包含的记录。提交事务的时间间隔越长,消费者在读取到消息之前需要等待的时间就越长,端到端延迟也就越高。
- 但是,消费者不需要缓冲未提交事务所包含的消息,因为broker不会将它们返回给消费者。由于消费者在读取事务时不需要做额外的工作,因此吞吐量不受影响。